Data Integration Challenges: What Goes Wrong and How to Fix It?
All data teams will eventually reach their breaking point when integrating data. Everything may be going smoothly, starting from an initial, sensible ETL process and some source systems. Eventually, months down the line, your team ends up battling schema drift across many databases, tracing lost data through transformation processes, and explaining to business users why the report still shows last week’s data. Identifying such problems early on in your data integration efforts is perhaps the most pragmatic thing a data team could do.
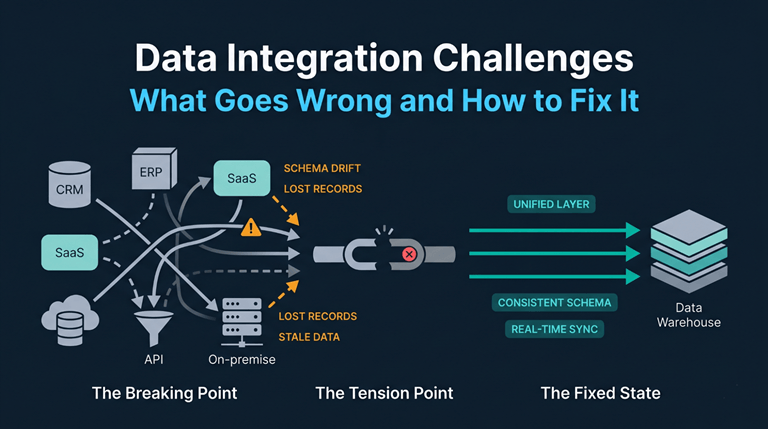
Why Data Integration Is Harder Than It Looks
Data integration is the process of bringing data from various sources into a single consolidated layer of information. This is an easy idea but hard to execute with all the different platforms like CRMs, ERPs, cloud databases, SaaS applications, APIs, and on-premise databases, each of which comes with its own model for data storage, update frequency, and connectivity protocols. The second you need any two of these platforms to communicate, things get sticky. Multiply that across twenty systems, and the scope of the problem becomes clear.
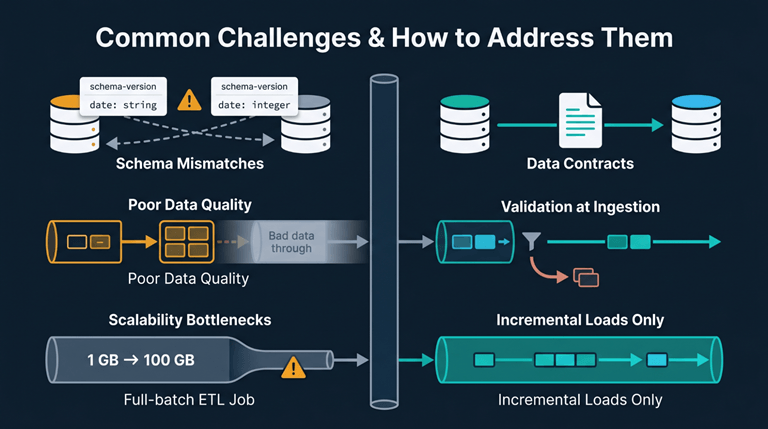
Common Challenges and How to Address Them
1. Schema Mismatches and Format Inconsistencies
Data representation is rarely similar in different schemas. For example, dates may have different encodings, customer IDs may have strings in one database and integers in another, and different fields have different names depending on the department and the time period. Mapping of schemas is a completely manual process that breaks down when there is a schema change in the source system.
The solution to this problem is to develop data contracts with source system owners before creating data pipelines. This eliminates many problems by ensuring that schemas, update schedules, and notification procedures are all understood in advance. The pipeline can automatically detect schema changes, as well.
2. Poor Data Quality at the Source
Integration itself doesn’t generate any issues regarding data quality. Duplicates, null fields, or mismatches can only be revealed during integration processes. Often, companies find out that their key data has been inconsistent for years in databases that were thought to be synchronized.
Looking into data quality as a separate phase in a pipeline proves to be useful in this context. The use of validation rules upon data ingestion, along with proper rejection and alerting procedures, makes this problem manageable.
3. Scalability Bottlenecks Over Time
A pipeline that runs at 1 GB per day will fail miserably at 100 GB. ETL jobs that ran under the cover of night during the first year will soon run within business hours in the third year. There’s no early warning sign that something’s wrong since the pipeline still runs, and everyone moves on. Once scaling becomes necessary, however, the architecture may be too well-established to fix.
Incremental loads are the answer since they don’t require all data to be processed each time. Only data that changes will be processed, ensuring that pipeline execution remains constant as data volume increases.
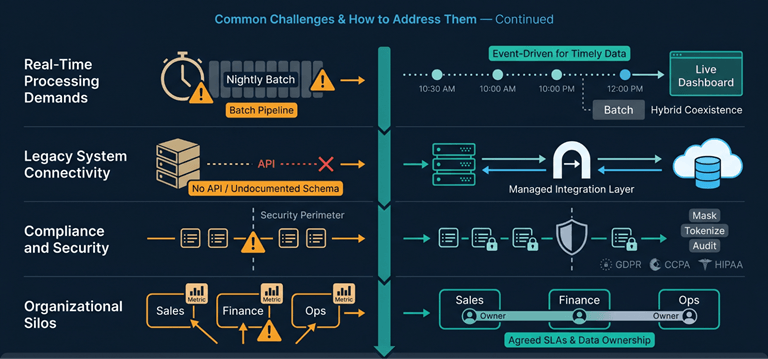
4. Real-Time Processing Demands
Most companies find themselves forced to move towards real-time or near-real-time integration due to fraud detection, operational dashboards, and personalization needs. Batch pipelines were never designed for such things. Streaming integration requires new tools, new error handling processes, and new monitoring, and batch-first organizations usually do not realize how big a change it is going to be.
The gradual approach to adopting event-driven architectures by building streaming integrations for timely data, while still using batch processes for other loads, is a good way to start.
5. Legacy System Connectivity
Legacy systems house important business information that was not built for current cloud environments. They lack APIs, have undocumented schema structures, and need custom connectors, which can be costly. Working with legacy systems may necessitate slow ingestion processes and export files.
For organizations at this stage, a managed data integration approach, where the connectivity, transformation logic, and pipeline maintenance are handled by a specialist team, reduces both the upfront effort and the ongoing operational burden of keeping legacy connections stable.
6. Compliance and Security Across Boundaries
Data traverses security boundaries as it moves across systems. Personal information, financial data, and medical data come under the purview of GDPR, CCPA, and HIPAA. Masking, tokenizing, and auditing must take place at each security boundary, and achieving this necessitates coordination between the engineering, legal, and security departments, which might have competing deadlines.
Incorporating compliance checks at the outset of the data pipeline is better and reduces rework of adding them later. Governance frameworks specifying ownership and policies for handling data allow compliance checks to be more easily automated.
7. Organizational Silos
Most of the integration challenges come from the organizational structure rather than technology. Various departments are responsible for various systems and their own priorities, and they hardly ever align or work together. Inevitably, there will be duplication of pipelines, contradictory definitions of metrics, and silos, not because it cannot be done technically, but because there is no agreement on who owns what. Data integration without approval from each business unit will lead to many issues with access.
Clarifying the issue of data ownership by having an owner designated for each source system and having agreed SLAs for modifications will mitigate organizational issues around integration.
Putting It Together
The vast majority of integration issues fall into one of several categories: data schema problems, poor data quality, inadequately scaled systems, and lack of coordination. Handling these up front will prevent most of the issues that hold up data teams. If your pipelines are already showing these symptoms, purpose-built data integration services can help engineering teams diagnose fragile integration layers and build systems that hold up as data volumes and source complexity grow.
Popular on OTW Right Now!


About The Author
Gagan Bhangu
Founder of otechworld.com and managing editor. He is a tech geek, web-developer, and blogger. He holds a master's degree in computer applications and making money online since 2015.